Data has transformed American healthcare. Every day in hospitals across the country, doctors improve outcomes with granular patient data from sources as diverse as electronic health records, smartphones, wearables, internet search patterns, and more. Aggregating patient-level data is yielding impressive results: we are able to diagnose more and rarer conditions than ever before, and treatments have become more targeted.
Using data science tools to better understand individual patients is tremendously exciting, but hospitals can benefit at least as much from using those same tools on themselves.
Health systems collect an immense amount of data about their operations: bed usage, emergency department (ED) wait times, patient flows through the hospital, etc. However, the methods used to analyze these data have not kept up with the volume of data collected. If system-level data is analyzed at all, it’s typically with traditional retrospective statistical methods.
For example, staffing is one of the most difficult problems in healthcare. Systems need to schedule staff a week or more in advance, before you know your patient load. Retrospective analysis can tell you what happened last week, last month, or last year: How many patients showed up to the ED with flu-like symptoms last October? How many of those patients were admitted? How many nursing hours did each of those admissions require? While this type of analysis can help you form simple heuristics, it is not a robust methodology for predicting what will happen next. Just because last flu season peaked in October does not mean that this year’s flu variant will peak at the same time. Ultimately, you’re forced to make an informed guess and hope for the best. Systems can end up overstaffed, waiting for a surge that doesn’t arrive. Or worse, they end up understaffed at a critical moment and need to call in expensive backup.
So, how can health systems better leverage their vast databases to improve outcomes?
Because reducing ED wait times is crucial to providing better care, most health systems have data on what times of day, what days of the week, and even what times of year their ED will be busiest. Retrospective analysis can highlight previous patterns, but can’t evaluate early indicators that this time could be different. By simulating entire human populations with realistic social dynamics, agent-based modeling makes that kind of prospective analysis possible. For example, we used publicly available COVID-19 data to forecast hospital demand on our platform, predicting ED visits, downstream hospital admissions, ICU usage, and facility-level alerts across a Michigan health system.
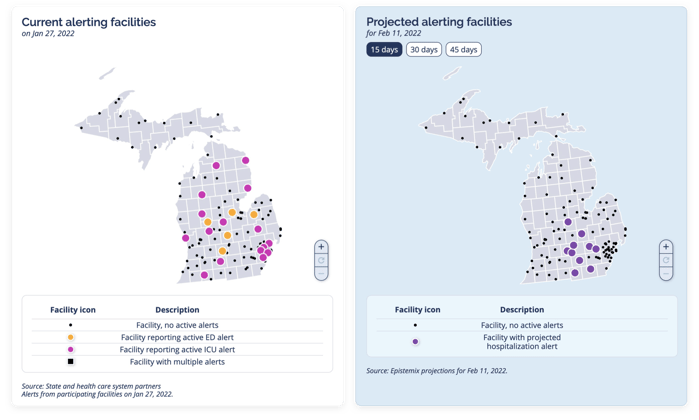
Below, you can see system-wide current and projected facility alerts where COVID-19 is expected to surge, giving leaders the insight they need to plan for resources and staffing weeks in advance.
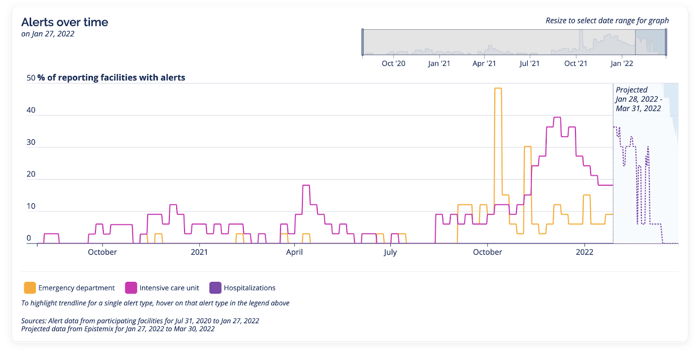
Here are the same historical and projected alerts over time.
And here are the system-wide historical and projected hospitalizations that drive the alerts.
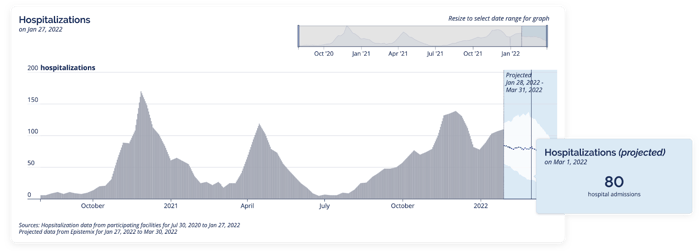
In the midst of an ongoing healthcare staffing crisis, these forecasts tell you what you need to know to get a jump start on scheduling permanent staff and booking travel nurses—in line with recommendations from the American Hospital Association to improve staffing and retention through strategic planning.
Over the past few decades, providers used patient-level data to improve individual health outcomes, and now you can start using system-level data to improve population health outcomes. Traditional reactive analytics can explain what happened yesterday, but don’t prepare you for tomorrow. As hospitals struggle to meet volatile demand, leveraging system-level data to plan ahead helps you ensure that there will be enough resources to deliver high quality care during surges and keep your staff focused and resilient.
Erin Zwick is a Director of Health & Disease Modeling at Epistemix.