At first blush, the idea of “synthetic data” seems nonsensical: artificially generated data that mimics the desired attributes of real data. If the whole point of using data is to calibrate your theories to the real world, then why would you want to use data you know isn’t real? In fact, some of the most powerful data science techniques depend on synthetic data that is realistic even though it isn’t real.
For example, machine learning algorithms are data hungry, requiring huge amounts of information to train models. Before you can train your algorithm, you have to acquire, clean, and post-process the training datasets, but often the right training data is expensive, privacy-infringing, incomplete, or simply unavailable. Even if you manage to get your hands on it, training data usually requires extensive cleaning and merging with disparate datasets, resulting in redundancies, biases, and complex post-processing.
Taking this a step further, if you’re training an AI to drive autonomous vehicles, you can’t rely entirely on real data because training cars how to drive requires enormous amounts of data about car crashes. So instead of crashing millions of cars on a test track, you generate synthetic data for those crashes to train the AI.
Beyond machine learning, synthetic data is crucial for building privacy-sensitive software. Engineers building finance and healthcare tools need data for development and testing, but personal financial and health information is highly sensitive and can’t be easily shared across teams even if it’s anonymized, so they generate representative synthetic data instead.
Synthetic data is also useful for simulating what might happen in the future, like when forecasting the stock market, climate, infectious disease outbreaks, the impact of a new technology, or the implications of a new strategy. These scenarios can’t be studied empirically because they haven’t happened yet, but running simulations on a rich substrate of representative synthetic data lets you model the spread of realistic outcomes in order to figure out what to do next.
Here at Epistemix, we run scenario-based simulations with our agent-based modeling platform. While techniques like machine learning allow you to discover subtle patterns in existing data, agent-based modeling lets you play out scenarios in a virtual world populated by virtual people—“agents”—so you can evaluate impact a priori. But those familiar with agent-based modeling know its flaws: most agent-based models are only loosely tethered to real data, so they tend to produce abstract projections and generic results.
How do we solve this problem? Synthetic data.
To simulate how a new product finds users or the consequences of a particular strategic decision or how a new virus spreads, we need to include every person in the United States in our model because their individual behaviors aggregate to generate the outcomes we’re interested in. Representing Americans as abstract “agents” would only achieve generic results because they lack attributes informed by real data, but collecting personal data on every individual American is both practically impossible and privacy infringing. Instead, we built a synthetic population that is statistically accurate to the census-block level in order to run realistic simulations with virtual people in a virtual world.
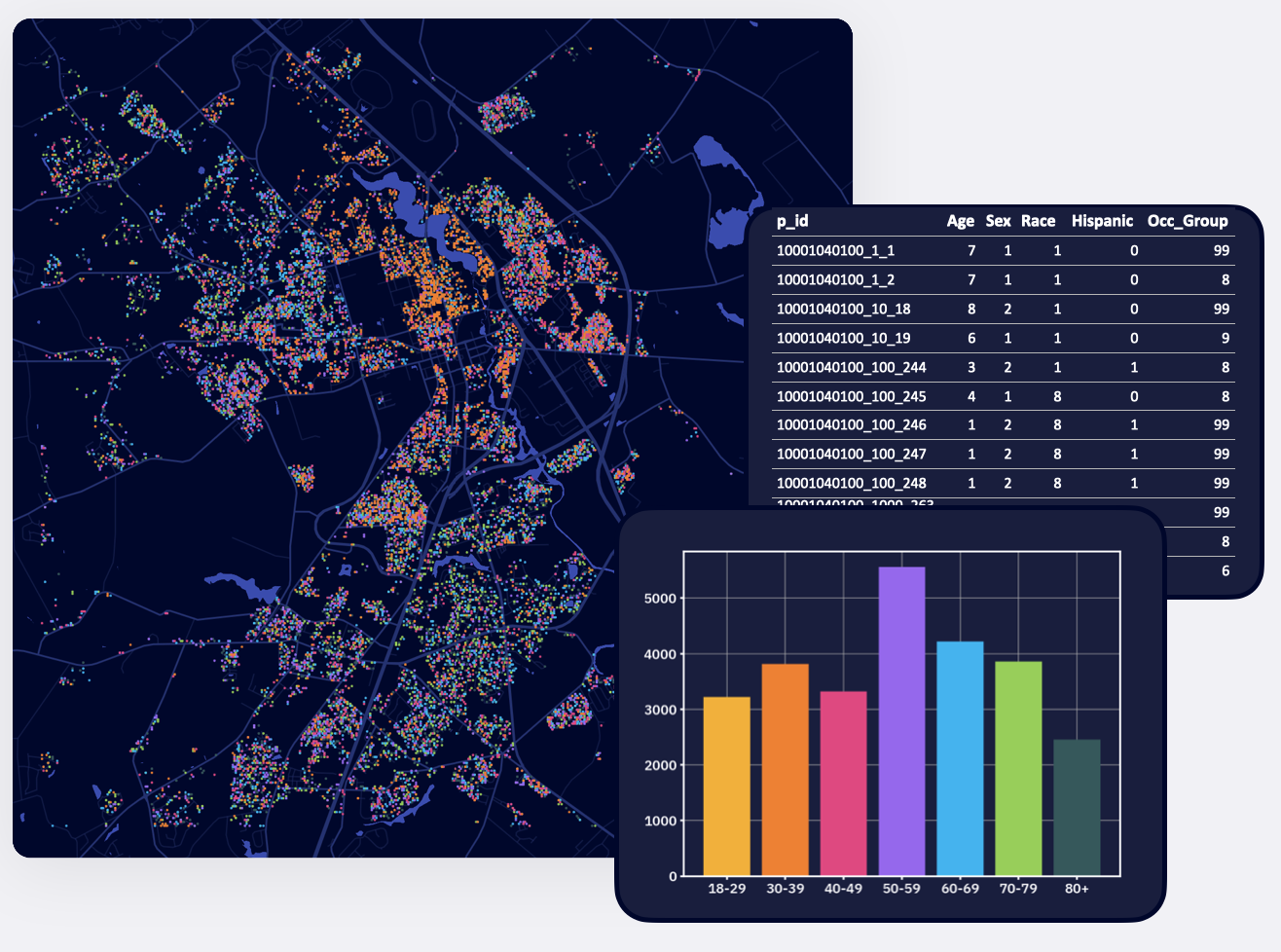
To create this synthetic population, we tapped a combination of sources. For individual agent characteristics, we used multiple datasets from the US Census Bureau including the American Community Survey, the Public Use Microdata Survey, and Commuter Flows. We assigned household locations based on satellite imagery of building footprints. Place information, including schools and workplaces, was generated using data from the National Center for Education Statistics and RTI. We integrated these datasets for each census tract in the United States to create agents and households with accurate demographic, socioeconomic, and geographic characteristics.
The resulting synthetic population accurately represents Americans’ age, sex, race, household size, household income, and household type (family or non-family), as well as their ethnicity, school enrollment status, school grade, occupation, health insurance status, level of household internet access, and the household’s number of vehicles. Each virtual member of the synthetic population has a realistic daily schedule for when they are at home, school, and work.
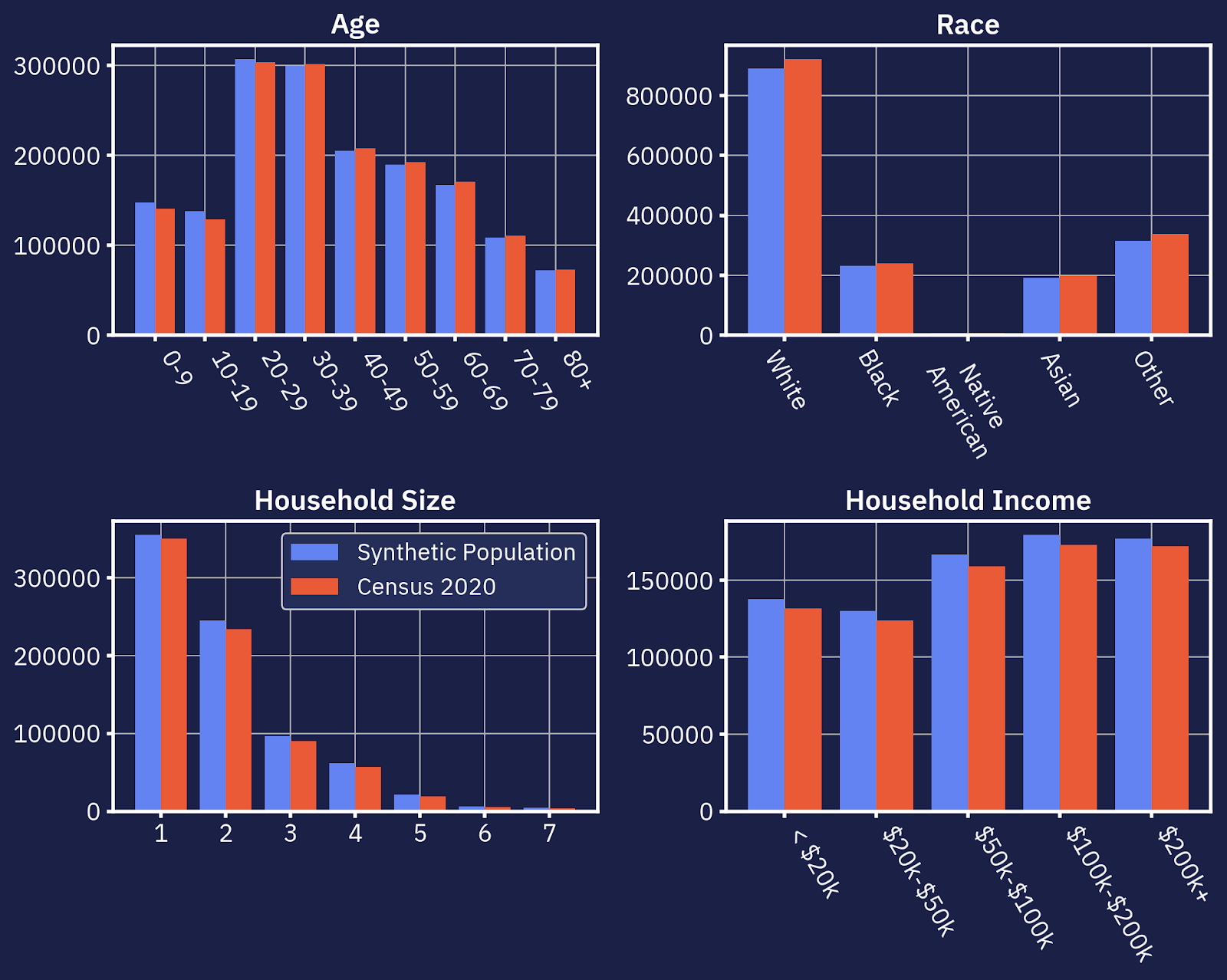
Below, you can see how tightly our synthetic population correlates to the latest U.S. Census.
With a realistic synthetic population under the hood of an agent-based modeling platform, new analyses are possible.
You can simulate any scenario that you can summarize into rules agents can follow. You can play out social, behavioral, and economic theories to optimize interventions, analyze risks, and plan ahead. You can instantly summarize characteristics of the United States population in any locality. For example, what is the joint distribution of household income by race and education level in Boulder, CO? The answer without synthetic data would come from multiple datasets that are incomplete, imbalanced, and not fully representative. Our synthetic dataset is designed to address these concerns by integrating disparate and diverse sources into a fully representative sample that exists in a simple data structure you can analyze easily and efficiently without the typical limitations of observed datasets. Further, the ways in which agents are linked through household membership, neighborhood location, and school/workplace attendance means you have a full-scale social network representative of every person and household in the United States at your fingertips. This combination of individual-level information embedded in a full-scale social network that is spatially realistic provides limitless analytical potential. You can even add external datasets to the synthetic population to predict any number of indicators, including, for example, consumer behavior and product demand across demographics and space.
Even better, you can identify emergent behavior. For example, in the world of infectious disease modeling, ordinary differential equation models predict a threshold level of transmissibility that a pathogen must have in order to invade a population. However, we know that this threshold varies across populations with different age distributions, contact structures, or risk levels. Our platform, harnessing its synthetic population, allows you to identify specific subpopulations where a disease can and can’t spread–i.e., when emergent properties affect the outcome we care about. The same logic applies across product adoption, disaster planning, and resource allocation: running simulations on top of a realistic synthetic population allows you to generate actionable, differentiated insights into the real world.
While the idea might seem counterintuitive, synthetic data is powering advances across fields as diverse as machine learning, autonomous vehicles, and fraud detection. When it comes to agent-based modeling, running simulations on a platform with a built-in synthetic population empowers data scientists to answer questions you could never answer before, like what if you launched a new product in a particular way, how a market might react to disruption, what the consequences of a specific decision might be, or why a given scenario plays out a certain way. Mapping out these possible futures in a realistic virtual world can reveal the best path forward.
Paige Miller is a data scientist at Epistemix.